Using OpenAI API to make a coffee barista — Part 2 (now using RAG)

Code available in: https://github.com/lfomendes/guaxinim-barista
Hello everyone!
This is the second part of my personal project of creating a personal barista to help coffee lovers to make the best cup of coffee possible. The first part can be seen here.
In the first part we created a simples coffee barista that can help you improve you coffee cup and respond to coffee related questions. Now I’m going to show how we can incorporate RAG to help the barista make fewer errors and provide reliable sources.
What is RAG and why use one?
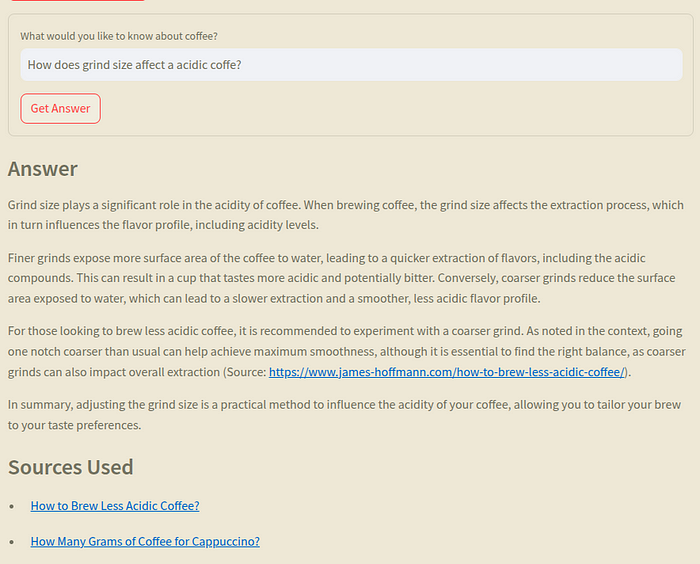
I asked ChatGPT for help with my acidic coffee problem on two different days, and I got two completely different answers! One day, it suggested making the grind more fine, and the next time, it told me to go coarser. This is what we call AI “hallucination” — when the model comes up with stuff that isn’t exactly true. Both sounded plausible, but I consulted my most trusted coffee specialist (James Hoffman) and found this post.
A coarser grind means less surface area is exposed to water during brewing, resulting in lower acid extraction. Try going one notch coarser than you normally would for maximum smoothness. Just be aware that coarser grinds can also impact overall extraction, so experiment to strike the right balance.
And that’s where Retrieval-Augmented Generation (RAG) comes in handy in AI. RAG helps make AI responses more accurate by data while generating answers. In the context of the personal barista app, this means it’s not just making stuff up — it’s pulling actual, relevant coffee info to help you get the best brew, every time. With RAG, the app offers solid coffee advice that’s both creative and well-grounded.
Creating a simple RAG
To address the problem of varying or incorrect answers, we incorporate RAG into our barista application.
RAG systems can be very complex with databases, many jobs and steps. For our coffee barista V2.0.0 I decided to start simple. So these were my tasks for this version.
- Gather documents from reliable sources
- Write a script that divides these documents into chunks. (pieces)
- Create text embeddings for each chunk and save them in a JSON file.
- During the app loading get this json file and put these embeddings into a Fasttext so we can do similarity search.
- Create embeddings from the user queries and use a similarity search to get the most similar chunks from these documents
- Change the prompt so it take these chunks into consideration while responding to the user
- Add the sources into the interface
Documents
Since this is the first version of our RAG, I downloaded three PDFs from the James Hoffman blog.
- HowtoBrewLessAcidicCoffee.pdf
- How to Make Tiramisu Coffee.pdf
- How Many Grams of Coffee for Cappuccino.pdf
We are just creating a MVP, if it works for these 3 we can incorporate more curated data afterwards easily.
Code
For the PDF processing, I created the processor.py script, which divides the texts into chunks, creates embeddings, and saves them into a JSON file.
To create the embeddings I used the Sentence Transformer since it is easy to use and have a good enough quality for this task. We load all-MiniLM-L6-v2, which is a MiniLM model finetuned on a large dataset of over 1 billion training pairs.
Our model is intended to be used as a sentence and short paragraph encoder. Given an input text, it outputs a vector which captures the semantic information. The sentence vector may be used for information retrieval, clustering or sentence similarity tasks.
def create_embeddings(chunks: List[str], model_name: str = 'all-MiniLM-L6-v2') -> List[List[float]]:
"""
Create embeddings for a list of text chunks using sentence-transformers.
Args:
chunks (List[str]): List of text chunks to create embeddings for
model_name (str): Name of the sentence-transformers model to use
Returns:
List[List[float]]: List of embeddings for each chunk
"""
model = SentenceTransformer(model_name)
embeddings = model.encode(chunks, show_progress_bar=True)
# Convert numpy arrays to lists for JSON serialization
return embeddings.tolist()And I changed all prompts to take the information into consideration
CONTEXT_PROMPT_TEMPLATE =
"""Context information is below.
---------------------
{context_str}
---------------------
Given the context information and your expertise as a professional barista,
provide a answer to the query.
Query: {query_str}
Answer: """With this we can see an answer from the barista citing the sources.
I also created a new section of the app so we can debug this similarity search. This new screen has a text input and it returns the chunks and titles with their similarity score. In the two images below you can check a good match and a bad match as example.
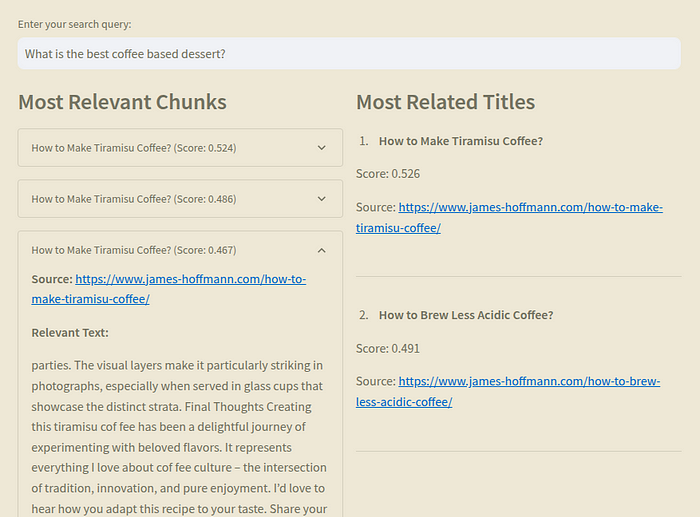
In this first example the input is about coffee and desserts. From the documents that we have, what we would expect is that the the chunks from the “How to Make Tiramisu Coffee” would be the most similar and it seems that our search return 3 chunks from this blog post. Great!
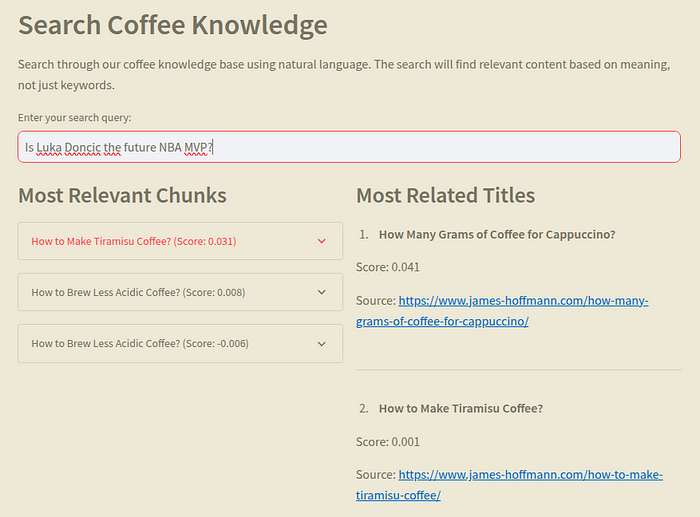
Now, for the second test I used a non-coffee relate question and we can see that the similarity scores are close to zero and one of them is even negative.
App flow
Now our barista app have two different flow, one that is offline. That is, we can run it only once to process all pdfs from a folder and save a json file.
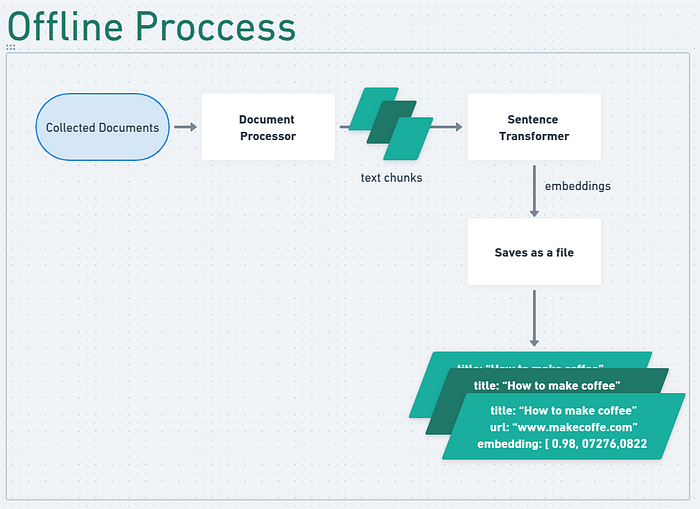
And a second flow that will load this json into the Fasttext, use this fasttext to do a similarity search for the chunks of information and incorporate them into the prompt.

Results
And here is a video of this new version of the app:
Now we can have a little more trust in our Barista, since he is studying from curated sources.
Nexts steps
Our Raccoon Barista is well on its way to becoming a reliable coffee companion. It now knows how to gather valuable information and respond to user queries, citing all sources used for transparency.
For the V3.0.0 I am planning to expand its information database and enhance interactivity, allowing users to engage in more dynamic conversations with the barista. I’m also considering writing a post on evaluating the quality of the barista’s answers.
I’d love to hear your thoughts on what additional features or improvements you’d like to see in our barista. Your suggestions are most welcome!
Until the next one!